DB 연동방법 4
1. 클래스내에서 직접 sql문 기술
2. 스프링이 지원하는 jdbcdao support 사용
3. mybatis 프레임워크사용
4. jpa 사용
요즘은 jpa를 가장 많이 사용하고, 가장 권장하는 추세라고 한다. 왜일까?
백엔드에서 데이터를 저장하고 조회하려면 데이터베이스를 활용해야 하는데, 백엔드에서 데이터베이스를 사용하는 프레임워크로 가장 많이 쓰이는 기술이 ‘Mybatis’와 ‘JPA' .
Java 기반의 Spring 또는 Springboot에서 데이터베이스를 사용하려면 두 가지 기술 중 하나를 사용해야 하기 때문에 Java 백엔드 개발자는 ‘Mybatis’와 ‘JPA’를 반드시 알아야 합니다.
데이터베이스 접속을 편하게 사용하기 위해 SQL Mapper 기술과, ORM(Object Relational Mapping) 기술을 제공합니다. 둘 다 DB와의 연동, 저장을 위한 기술이며, SQL Mapper는 ‘개발자가 작성한 SQL 실행 결과를 객체에 매핑’시켜주는 프레임워크이며, ORM은 객체와 DB의 데이터를 ‘자동으로 매핑’시켜주는 프레임워크를 말합니다.
SQL Mapper 기술을 제공하는 것이 ‘MyBatis’이며, ORM 기술을 제공하는 것이 ‘JPA(Java Persistence Api)’입니다. 두 가지 기술은 모두 데이터를 관계형 데이터베이스에 저장, 즉 영속화(Persistence) 시킨다는 측면에서는 동일하지만, 서로 다른 접근 방식을 채택하고 있다.
MyBatis는 개발자가 작성한 SQL 문을 Java 객체로 자동으로 매핑 시켜주는 프레임워크.
JPA는 이보다 한발 더 나아가서 SQL 문까지 자동으로 생성해 주고, DB 데이터와 Java 객체를 매핑 시켜주는 기술입니다. SQL 문장 작성이 필요 없으니 MyBatis보다 한 단계 더 자동화되어 더 편리함과 반복작업을 없애준다.
JPA가 생겨난 이유
데이터베이스는 데이터 중심의 구조를 가지고 있고, Java는 객체지향적인 구조로 관리되기 때문에 둘 사이에 데이터를 직접적으로 쉽게 가져오거나 쉽게 저장하는 방법이 존재하지 않았다. JPA의 접근 방식은 이런 ORM(Object-Relational Mapping) 기술을 의미합니다. 즉, 객체와 데이터베이스 간의 매핑 기술을 의미하며, Java 개발자가 좀 더 객체지향 관점에서 개발할 수 있게 하고, 개발을 용이하게 해주어서 DB와 Java 간의 불일치를 해소해 준다.
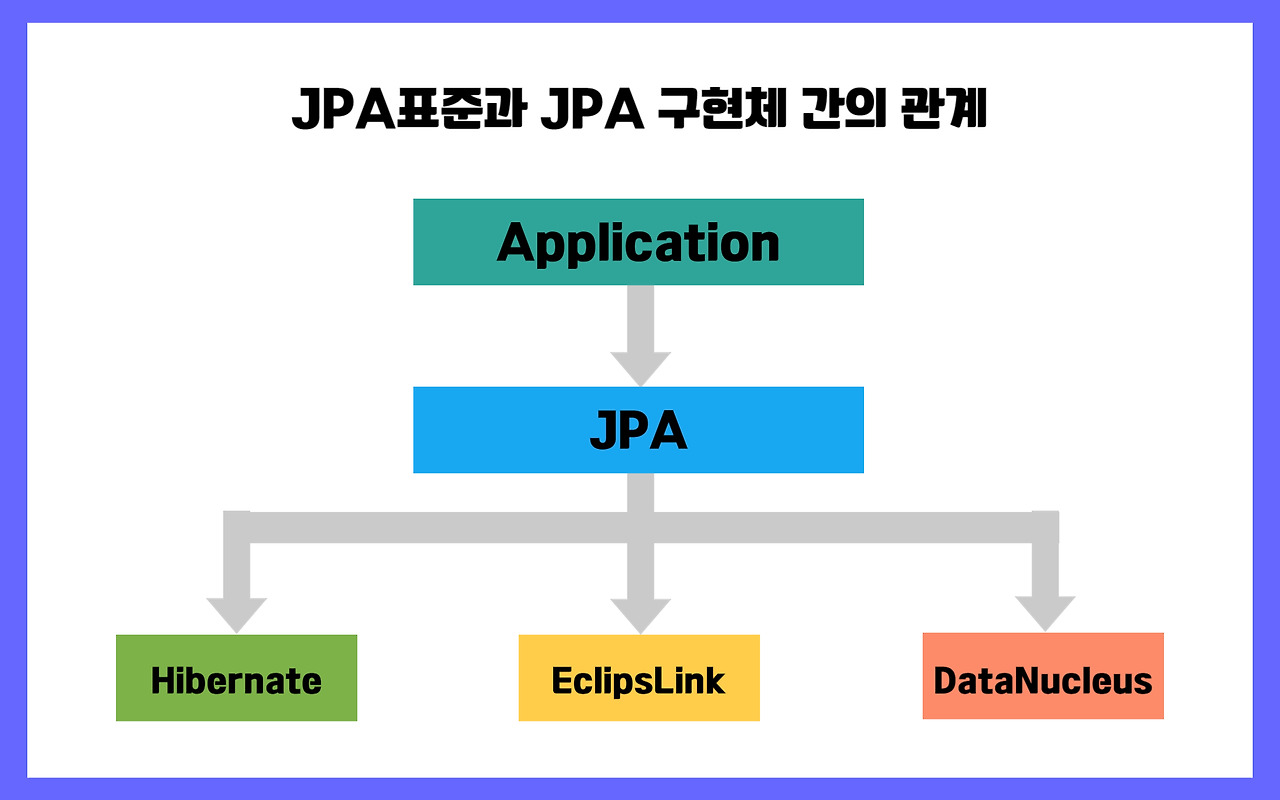
이러한 ORM 기술을 실제 구현해서 만들어진 프레임워크가 Hibernate. Java와 DB 데이터 간의 매핑을 자동화해주어서 개발자는 SQL 문을 작성할 필요가 없어지고, DB가 바뀌어도 DB에 따라 새로운 SQL을 작성할 필요가 없이 Hibernate에서 DB에 맞는 적합한 SQL 문을 생성해 준다.
pom.xml 작업
필요한 소스코드를 해당 링크를 통해 얻어온다.
https://central.sonatype.com/artifact/org.hibernate/hibernate-entitymanager
해당 에러문구가 콘솔창에 지속적으로 뜬다. 이번기회에 pom에 필요한 소스코드 추가하고 가보자.
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
https://central.sonatype.com/artifact/ch.qos.logback/logback-classic

db작업
create database gooddb;
use gooddb;
create table mem (num int(11) primary key, name varchar(10), addr varchar(50));
insert into mem values(1, '유비', '강남구 역삼동');
++ insert into mem values(2, '관우', '강남구 압구정동');
insert into mem values(3, '장비', '서초구 서초동');


sql문은 원래 대문자로 작성. 그래서 테이블명도 소문자로 적어도 알아서 대문자로 인식.
그러니 mem이 아니라 MEM이다.
MemDto.java
package pack.model;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
@Entity
@Table(name="mem")
public class MemDto {
@Id
private int num;
@Column(name="name", nullable=true)
private String name;
private String addr;
}
@Data
무분별하게 @Data를 사용하면 @ToString, @EqualsAndHashCode, @Getter, @Setter, @RequiredArgsConstructor 도 같이 사용되며 발생하는 문제들이 생길 수 있다.
1) @Setter
setter의 무분별한 사용은 객체의 안전성을 보장하기 어렵게 만든다.
setter를 사용함과 동시에 객체는 언제든지 변경될 수 있는 상태로 변하기 때문이다.
2. @ToString
To String 메서드를 만들지 않고 사용할 수 있게 하는 @ToString은 JPA와 같은 ORM을 사용할 때 문제가 될 수 있다.
예를 들어 두개의 모델이 있다고 하자.
@Data
public class Parents{
String name;
int age;
List<Sun> suns;
}
@Data
public class Sun{
String name;
int age;
Parent parent;
}
이런 경우에는 서로 간의 ToString이 무한대로 호출되어 stackoverflow가 발생할 수 있다. 그러므로 @Data 보다는 필요에 맞춰 안에 들어가는 요인들을 생각해 잘 사용할 수 있도록 하자.
@Builder
빌더패턴. 권장.
@NoArgsConstructor
기본생성자선언
@AllArgsConstructor
파라미터가있는 생성자선언
이 넷은 한 묶음이라고 생각하면 된다.
@Entity와 @Table
JPA를 사용하여 데이터베이스와 객체 간의 매핑을 설정하고, 데이터베이스에서 데이터를 조회, 저장, 수정, 삭제하는 데 필수적인 역할을 해주는 어노테이션. 이를 통해 객체 지향적인 접근 방식으로 데이터베이스를 다룰 수 있다.
@Entity
@Entity 어노테이션은 클래스를 JPA가 관리하는 엔티티로 지정한다.
즉, 데이터베이스 테이블과 매핑되는 객체.
JPA에서 관리되는 모든 클래스는 @Entity 애노테이션을 필수적으로 가져야 한다.
이 어노테이션을 클래스에 추가하면, 해당 클래스의 객체가 데이터베이스에 저장될 수 있고, JPA가 이 객체를 관리할 수 있다.
@ Table
엔티티와 매핑할 테이블을 지정한다.
@Table(name = "mem")의 경우, MemDto 클래스가 mem이라는 이름의 데이터베이스 테이블과 매핑됨을 의미.
물리적 테이블명 (Physical Table Name):
db 서버에 실제로 존재하는 테이블이름. db는 실제로 이 이름으로 테이블생성하고 관리한다.
논리적 테이블명 (Logical Table Name):
애플리케이션 코드나 개발자가 사용하는 테이블의 이름. 주로 객체 관계 매핑(ORM)에서 사용된다.
보통 실제 데이터베이스에서 사용하는 테이블명은 데이터베이스 시스템이나 관리자가 정하는 것이지만, ORM을 사용할 때는 논리적 테이블명을 정의하여 애플리케이션의 일관성을 유지하며 객체 지향적인 접근을 할 수 있다. @Table(name = "mem")에서의 "mem"은 이 논리적 테이블명을 나타내며, 해당 엔티티가 매핑될 데이터베이스의 테이블 이름으로 사용되는것.
@Id
pk칼럼에 붙인다.
@Column(name="", nullable="")
만약 db 컬럼명과 전역변수명이 다를경우, name으로 매핑.
nullable: 허용여부.
DB dialect
ANSI SQL
SQL(Structured Query Language) 이란 관계형 데이터베이스에 정보를 저장하고 처리하기 위한 프로그래밍 언어.
MS-SQL, Oracle, MySQL,PostgreSQL 등 다양한 RDBMS가 있다. 이렇게 다양한 DBMS Vendor 가 존재하는 만큼 서로 자신만의 고유한 SQL 을 가집니다.이에 따라 표준화된 SQL 에 대한 필요성이 생겼으며 미국 표준 협회(ANSI) 에서 ANSI SQL 을 통해 표준화된 SQL 을 정립하였다.

마리아디비 다이렉트에 맞게 알아서 돌아가게 해준다.
즉 db가 변해도(오라클, 마리아디비, 안씨 sql)이어도 소스는 안 바뀌어도 된다. 알아서 환경바꿔줌. 짱!
이게 하이버네이트의 가장 큰 장점
Debug

해결위해 logback..xml 파일 추가함.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="STDOUT" />
</root>
<!-- 특정 패키지의 로그 레벨을 조정할 수 있다 -->
<logger name="org.hibernate" level="WARN" />
</configuration>
로그레벨이란?
로그 레벨(Log Level)은 로그 메시지의 중요도를 나타내는 수준을 의미한다.
로그 레벨은 로깅 시스템에서 사용되며, 로그 메시지의 중요도에 따라 해당 메시지를 기록할지 결정하는 데 사용된다.
로그레벨 순서
TRACE > DEBUG > INFO > WARN > ERROR > FATAL
1) TRACE
- 가장 상세한 로그 레벨로, 애플리케이션의 실행 흐름과 디버깅 정보를 상세히 기록한다. 주로 디버깅 시에 사용된다.
2) DEBUG
- 디버깅 목적으로 사용되며, 개발 단계에서 상세한 정보를 기록한다.
- 애플리케이션의 내부 동작을 이해하고 문제를 분석하는 데 도움을 준다.
3) INFO
- 정보성 메시지를 기록한다.
- 애플리케이션의 주요 이벤트나 실행 상태에 대한 정보를 전달한다.
4) WARN
- 경고성 메시지를 기록한다.
- 예상치 못한 문제나 잠재적인 오류 상황을 알리는 메시지이다.
- 애플리케이션이 정상적으로 동작하지만 주의가 필요한 상황을 알려준다.
5) ERROR
- 오류 메시지를 기록한다.
- 심각한 문제 또는 예외 상황을 나타내며, 애플리케이션의 정상적인 동작에 영향을 미칠 수 있는 문제를 알린다.
6) FATAL
- 가장 심각한 오류 메시지를 기록한다.
- 애플리케이션의 동작을 중단시킬 수 있는 치명적인 오류를 나타낸다.
- 일반적으로 이러한 오류는 복구가 불가능하거나 매우 어려운 상황을 의미한다.
이번 프로젝틔 경우, WARN단계로 설정해주었다.

콘솔에 출력해보면 전보다 과정이 덜 출력됨을 확인가.(그 전 디버그수준, 즉 logback.xml 파일 추가전엔 디버그~ 다 나왔다.)
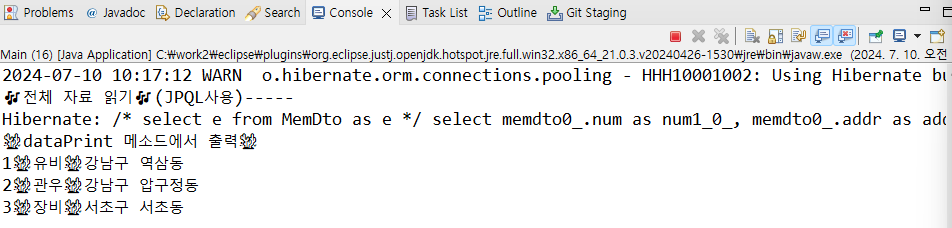
자 그럼 다시 db 연동 부분으로 돌아와서 jpql문으로 출력해보자.
전체자료, 부분자료 읽기
@Repository
public class DataImpl implements DataInterface{
@Override
public List<MemDto> selectDataAll() {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
List<MemDto> list = null;
try {
System.out.println("\n💦부분 자료 읽기💦(단일엔티티) find()메소드사용-----");
MemDto mdto= em.find(MemDto.class, 2);
System.out.println(mdto.getNum()+ "💦"+mdto.getName()+ "💦"+mdto.getAddr());
System.out.println("\n💦💦부분 자료 읽기(복수엔티티)💦💦");
List<MemDto> listPart = findByAddr(em, "강남");
for(MemDto m: listPart) {
System.out.println(m.getNum()+ "💦💦"+m.getName()+ "💦💦"+m.getAddr());
}
System.out.println("\n🎶전체 자료 읽기🎶(JPQL사용)-----");
list = em.createQuery("select e from MemDto as e", MemDto.class).getResultList();
} catch (Exception e) {
tx.rollback();
System.out.println("err : "+e);
} finally {
em.close();
emf.close();
}
return list;
}
public List<MemDto> findByAddr(EntityManager em, String ss){
String jpql = "SELECT m FROM MemDto m WHERE m.addr LIKE :ss";
TypedQuery<MemDto> query = em.createQuery(jpql, MemDto.class);
query.setParameter("ss", ss+"%");
return query.getResultList();
}
persistence.xml
드라이버 속성에 대해 적힌 파일.
META-INF 폴더 안에 위치한다.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<property name="javax.persistence.jdbc.driver"
value="org.mariadb.jdbc.Driver" />
<property name="javax.persistence.jdbc.user" value="root" />
<property name="javax.persistence.jdbc.password" value="123" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mariadb://localhost:3306/gooddb" />
<property name="hibernate.dialect"
value="org.hibernate.dialect.MariaDBDialect" />
<property name="hibernate.connection.pool_size" value="10" />
<!-- 옵션 -->
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.use_sql_comments" value="true" />
</properties>
</persistence-unit>
</persistence>여기서 persistence-unit name = hello.
따라서 createEntityMangeerFactory ()에서 "hello"라고 적어주게 된다.
entityManager
엔티티의 생명주기 관리. crud를 수행한다.
transaction
transaction을 관리하는 인터페이스.
전체자료 읽기
Hibernate ==> select e from MemDto as e : rdbms 종류에 관계없이 공통적으로 사용.
hibernate가 DBDialect로 보고 실제sql문으로 변환 ==>
select memdto0_.num as num1_0_, memdto0_.addr as addr2_0_, memdto0_.name as name3_0_ from mem memdto0_;
부분자료 읽기 - 단일엔티티
public find(Class<T> entityClass, Object pk) 이런 메소드가 이미 존재한다. 존재하는 find()메소드 사용.
부분자료 읽기 - 복수엔티티
findByAddr() : 특정 접두사 ss로 시작하는 레코드읽기.
TypedQuery<entity> query = e.createQuery(jpql, emetity클래스) : JPQL을 작성하고 실행하는 역할
query.setParameter("ss", ss+"%"); : sql의 like연산수행. 검색문자%
hibernate: SELECT m FROM MemDto m WHERE m.addr LIKE :ss
SQL문 : select memdto0_.num as num1_0_, memdto0_.addr as addr2_0_, memdto0_.name as name3_0_ from mem memdto0_ where memdto0_.addr like ?
궁금해서 jpql문으로 cmd창에 쳐봤다.

오! 같은 결과를 출력해준다.
레코드추가 insert, 수정 update, 삭제 delete
try {
// 레코드추가
tx.begin();
MemDto dto1 = new MemDto();
dto1.setNum(4);
dto1.setName("호빵맨");
dto1.setAddr("서초구 방배동");
em.persist(dto1);
tx.commit();
//레코드 수정
tx.begin();
MemDto dto2= em.find(MemDto.class, 4);
dto2.setName("세균맨");
tx.commit();
//레코드 삭제
tx.begin();
MemDto dto3= em.find(MemDto.class, 4);
em.remove(dto3);
tx.commit();
레코드 추가
insert는 오직 1개만 가능하다. 성공하면 1, 실패하면 0.
hibernate: insert pack.model.MemDto
sql문: insert into mem (addr, name, num) values (?, ?, ?)

레코드 수정
Hibernate: select memdto0_.num as num1_0_0_, memdto0_.addr as addr2_0_0_, memdto0_.name as name3_0_0_ from mem memdto0_ where memdto0_.num=?
SQL문: update pack.model.MemDto update mem set addr=?, name=? where num=?

레코드 삭제

JPQL 연습
부서별 인원수 출력
Jpql문
result = em.createQuery("select j.buser_num, count(j.jikwon_no) from JikDto as j group by j.buser_num", Object[].class).getResultList();
jpql에서는 칼럼명에 별명을 줄 수 가 없다. 그래서 jpql문으로 count를 하고나선, 객체의 첫번째 값, 두번째 값을 찍어줘야한다.
for(Object[] obj: result) {
String buserNum = (String)obj[0];
Long cntJikwon = (Long)obj[1];
System.out.println(buserNum+ ": "+ cntJikwon);
JOIN 작업
// JPQL 사용
String jpql = "select j.jikwonNo, j.jikwonName, b.buserName, j.jikwonIbsail "
+ "from Jikwon j join j.buser b";
TypedQuery<Object[]> query = em.createQuery(jpql, Object[].class);
List<Object[]> results = query.getResultList();
for (Object[] r : results) {
int year = getYearMy((Date)r[3]);
System.out.println(r[0] + " " + r[1] + " " + r[2] + " " + year);
}
// Native SQL 사용
String sql = "select jikwon_no, jikwon_name, buser_name, year(jikwon_ibsail) "
+ "from jikwon inner join buser on buser_num=buser_no";
Query query2 = em.createNativeQuery(sql);
List<Object[]> results2 = query2.getResultList();
for (Object[] r : results2) {
System.out.println(r[0] + " " + r[1] + " " + r[2] + " " + r[3]);
}
jpql을 쓸 경우, 별명을 붙일수도 없고 native sql문처럼 바로 year()이런 작업을 해 줄 수가 없다.
그런 단점이 있는데도 불구하고, jpql을 쓰는 이유는?
모든 db에 맞게 변형이 된다는 점 때문!
Entity 와 Dto를 사용하는 목적
Entity: @Entity 어노테이션을 통해 DB의 테이블과 직접 매핑되는 클래스. RDBMS 종류로부터 독립적으로 사용하기 위한 객체
DTO: DB와 직접적인 매핑을 갖지 않음. 주로 계층 간(ex. 서비스 계층에서 클라이언트로) 데이터 전송이 목적
<Entity 대신 DTO 사용하는 이유>
- 보안: 데이터베이스 구조와 직접적으로 연결된 Entity를 외부에 노출하는 것은 보안상 위험할 수 있다.
- 불필요한 데이터 노출 방지: Entity에는 클라이언트가 필요로 하지 않거나 노출되어서는 안 되는 데이터가 포함될 수 있는데, DTO를 사용하면 필요한 데이터만 전송 가능
- 유연성: Entity와 달리 DTO는 다양한 형태로 데이터를 가공하여 전송 가능. 클라이언트의 요구에 맞게 데이터를 변형하여 제공 가능
정리하자면,
Entity는 DB와 직접 매핑되는 클래스이고, DTO는 Entity를 기반으로 필요에 따른 데이터 가공 및 전송을 목적으로 사용되는 객체이다. 따라서 일반적으로 service 계층에서는 Entity를 조회하여 DTO로 변환하고, 데이터를 외부에 노출한다.
참고할 글 링크
https://www.elancer.co.kr/blog/view?seq=231
JPA vs Mybatis, 현직 개발자는 이럴 때 사용합니다. I 이랜서 블로그
서버에서 데이터 베이스를 효율적으로 사용하기 위해 사용하는 JPA와 Mybatis를 실무에서는 언제 어떻게 사용할까요? 이랜서에서 알려드립니다. I 소트프웨어, 소프트웨어 개발자, 네이버 소프트
www.elancer.co.kr
https://ttl-blog.tistory.com/112
[JPA] 엔티티 매핑 - @Entity, @Table
@Entity JPA에서 엔티티란 쉽게 생각하면, DB 테이블에 대응하는 하나의 클래스라고 생각할 수 있습니다. @Entity가 붙은 클래스는 JPA가 관리해주며, JPA를 사용해서 DB 테이블과 매핑할 클래스는 @Entity
ttl-blog.tistory.com
https://happymemoryies.tistory.com/45
【JPA】엔티티 매핑(Entity Mapping) - @Entity, @Table
객체와 테이블 맵핑을 담당하고 있는 @Entity 와 @Table 어노테이션에 대해서 공부한 내용을 정리해 봅니다. (기본 내용 출처는 자바 ORM 표준 JPA 프로그래밍 책 입니다.) @Entity JPA에서 테이블과 매핑
happymemoryies.tistory.com
[Spring JPA ] 데이터베이스 방언(Dialect) 이란?
안녕하세요 오늘은 스프링 JPA 에서 핵심적인 기능을 하는 데이터베이스 방언(Dialect) 에 대해 알아보겠습니다 👨💻sql(structured query language) 이란 관계형 데이터베이스에 정보를 저장하고 처리
velog.io
https://sharonprogress.tistory.com/198
로그 레벨(Log level)이란? 로그레벨 설정하기
1. 로그 레벨(Log level)이란?로그 레벨(Log Level)은 로그 메시지의 중요도를 나타내는 수준을 의미한다.로그 레벨은 로깅 시스템에서 사용되며, 로그 메시지의 중요도에 따라 해당 메시지를 기록할
sharonprogress.tistory.com
[JPA] JPQL이란? 사용방법, 기본 문법 총 정리
JPQL (Java Persistence Query Language)이란 ? JPQL은 엔티티 객체를 대상으로 하는 쿼리 언어이다. JPQL의 문법을 보면 다음과 같다. (나이가 18살 이상인 유저를 조회) select u from User as u where u.age > 18 JPQL은 SQL
hstory0208.tistory.com
https://blog.naver.com/hyoseonee0729/223509158611
[Spring Framework] JPA로 DB 연동하는 방법
src/main/resources > META-INF > persistence.xml <property name="hibernate...
blog.naver.com
'Backend > Spring' 카테고리의 다른 글
| @MVC DB연동 1 (0) | 2024.07.16 |
|---|---|
| thymeleaf layout. 머릿글 바닥글. th:block. (0) | 2024.07.16 |
| DB 연동3/4_mybatis. lombok annotation. (0) | 2024.07.14 |
| DB 연동 2/4_ JdbcDaoSupport (1) | 2024.07.14 |
| DB 연동1/4_ 클래스내에서 직접 sql문 적기 (0) | 2024.07.14 |